说在前面的话:
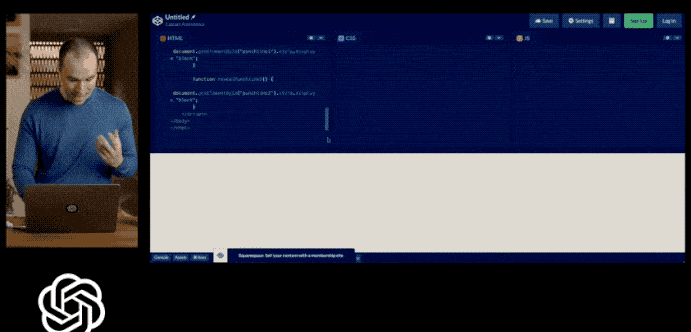
一个月前,OpenAI向外界展示了GPT-4如何通过手绘草图直接生成网站,令当时的观众瞠目结舌。
在GPT-4发布会之后,相信大家对ChatGPT的对话能力已有所了解。圈内的朋友们应该已经亲身体验过无论是文本生成、编写代码,还是上下文关联对话能力,这些功能都一次又一次地震撼着我们。
还记得发布会上,GPT-4展示的多模态能力,输入不仅仅局限于文字,还可以包括文本和图像,让我大开眼界。
例如:画个网站的草图,GPT4 就可以立马生成网站的 HTML 代码。
然而,时光荏苒!OpenAI至今尚未提供发布会上展示的多模态处理能力!
原本以为我们还需要再等上一段时间才能看到这一功能的更新,然而意想不到的是,我发现了这样一个项目。
这个项目被称为MiniGPT-4,由著名的阿卜杜拉国王科技大学的几位博士研究生共同完成。
更为重要的是,该项目完全开源!效果如视频中所展示的那样:
MiniGPT-4在线体验DEMO
MiniGPT-4能够支持文本和图像输入,成功实现了多模态输入功能,实在令人叹为观止!
GitHub项目地址:https://github.com/Vision-CAIR/MiniGPT-4
在线体验链接:https://minigpt-4.github.io
另外作者还提供了网页 Demo,可以直接体验(这酸爽?):
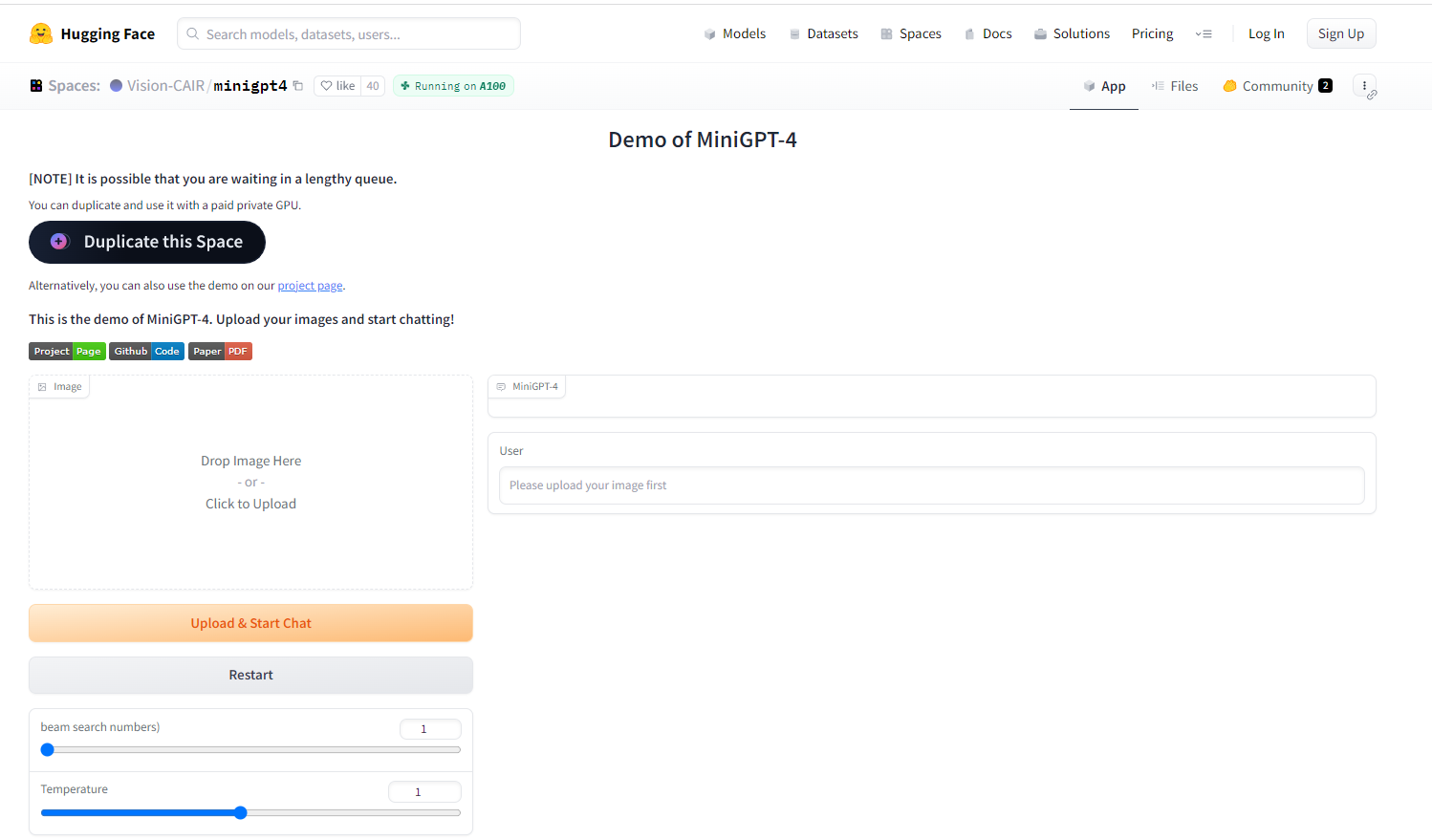
MiniGPT-4介绍
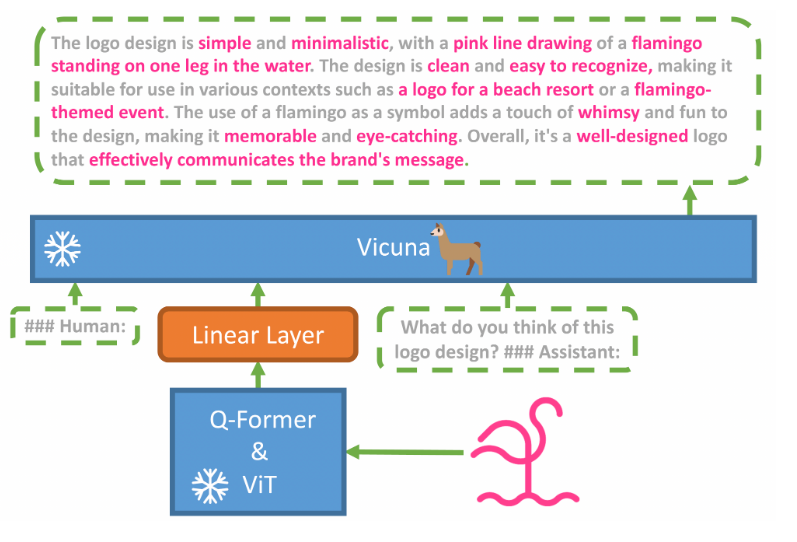
- MiniGPT-4利用一个投影层将BLIP-2的冻结视觉编码器与冻结的LLM(Vicuna)对齐。
- 我们分两个阶段训练MiniGPT-4。第一个传统预训练阶段使用大约500万个图像-文本对,在4个A100显卡上训练10小时。在第一阶段之后,Vicuna能够理解图像。但是,Vicuna的生成能力受到严重影响。
- 为解决这个问题并提高可用性,我们提出了一种新颖的方法,通过模型本身和ChatGPT共同创建高质量的图像-文本对。基于此,我们创建了一个小型(总共3500对)但高质量的数据集。
- 第二个微调阶段在该数据集的会话模板上进行训练,以显著提高其生成可靠性和整体可用性。令我们惊讶的是,这个阶段在计算上非常高效,仅使用单个A100花费约7分钟。
- MiniGPT-4展现出许多类似于GPT-4演示的视觉-语言能力。
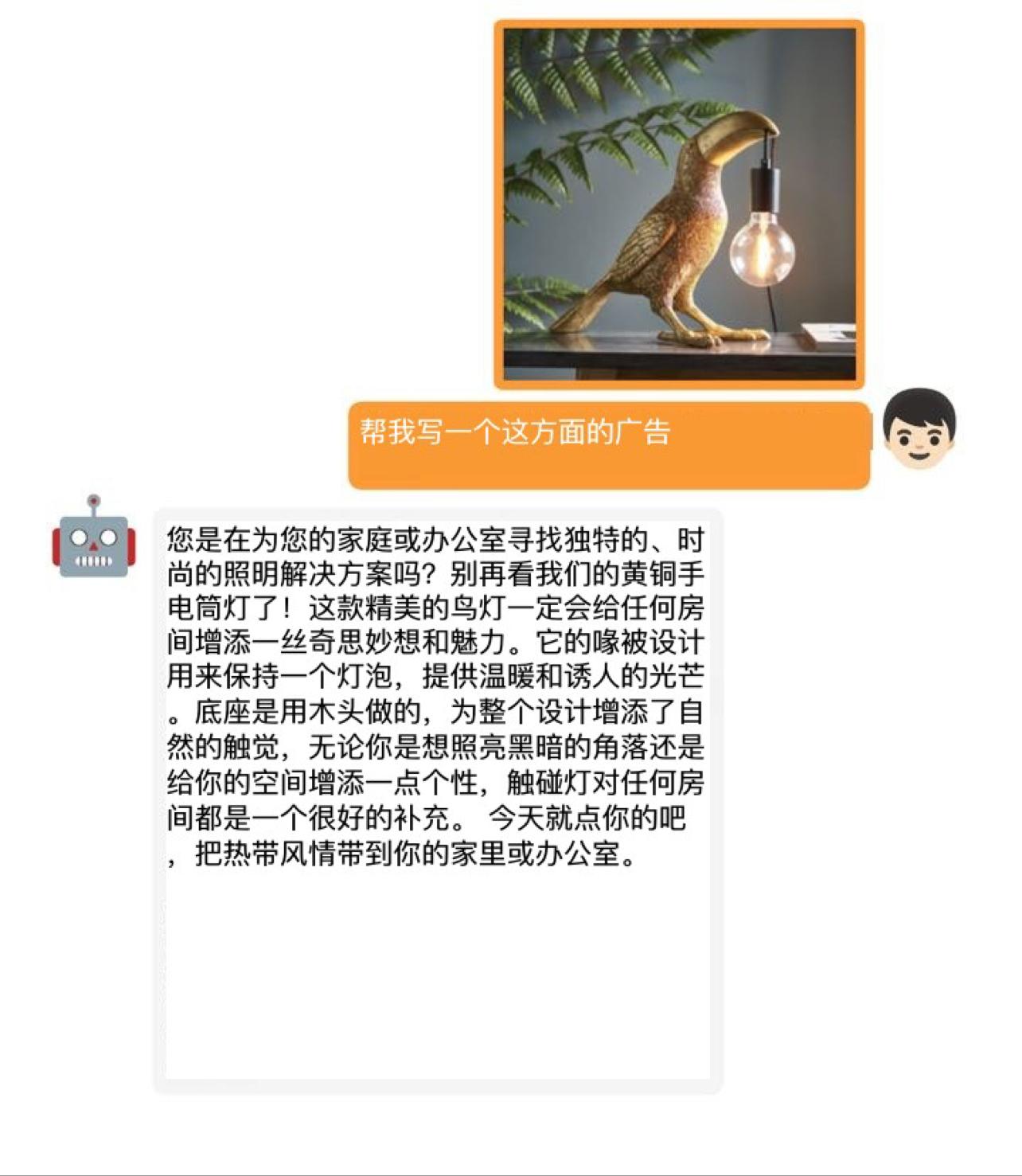
官方案例演示:
接下来,我将为大家展示几个示例。

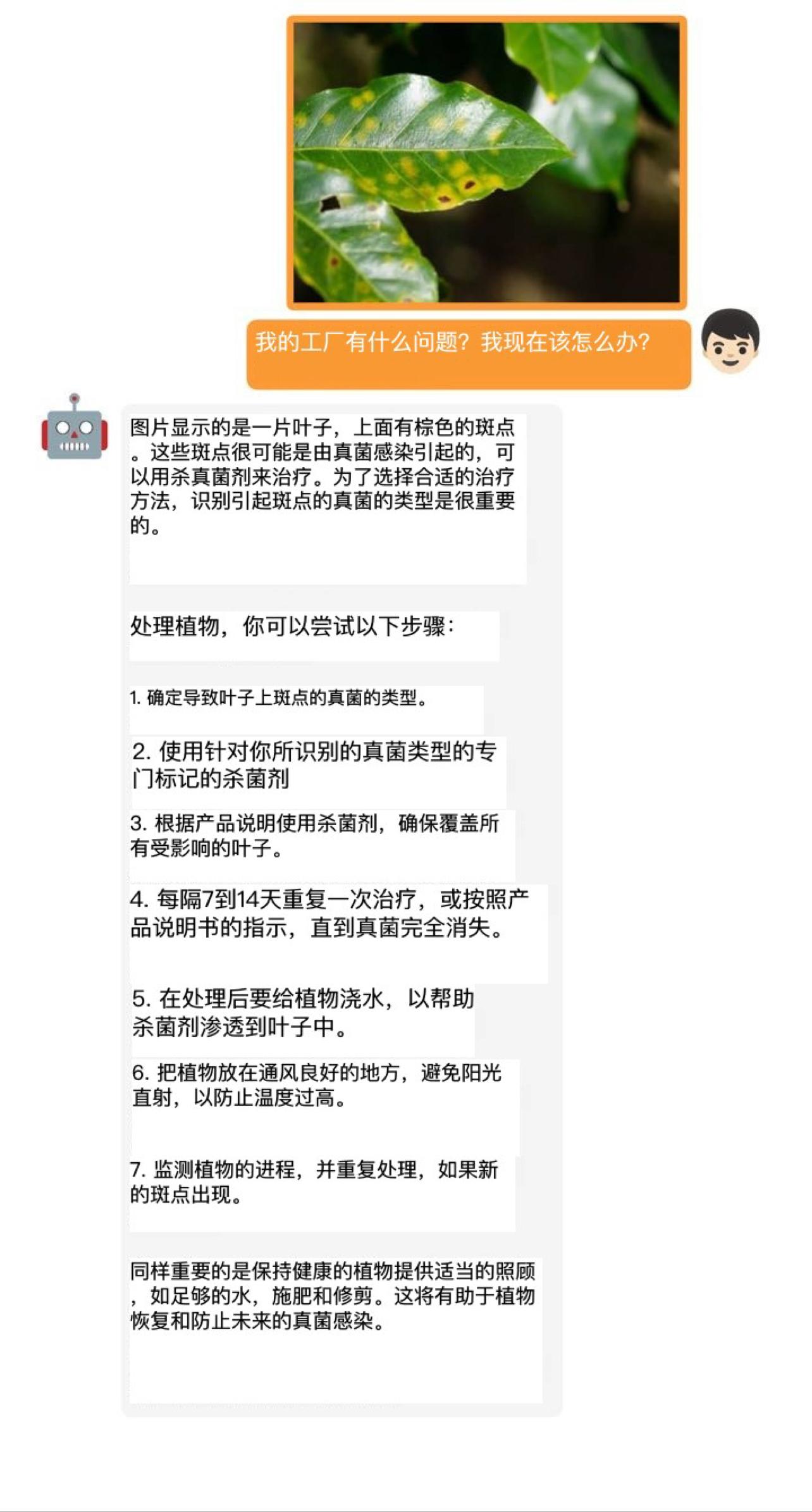
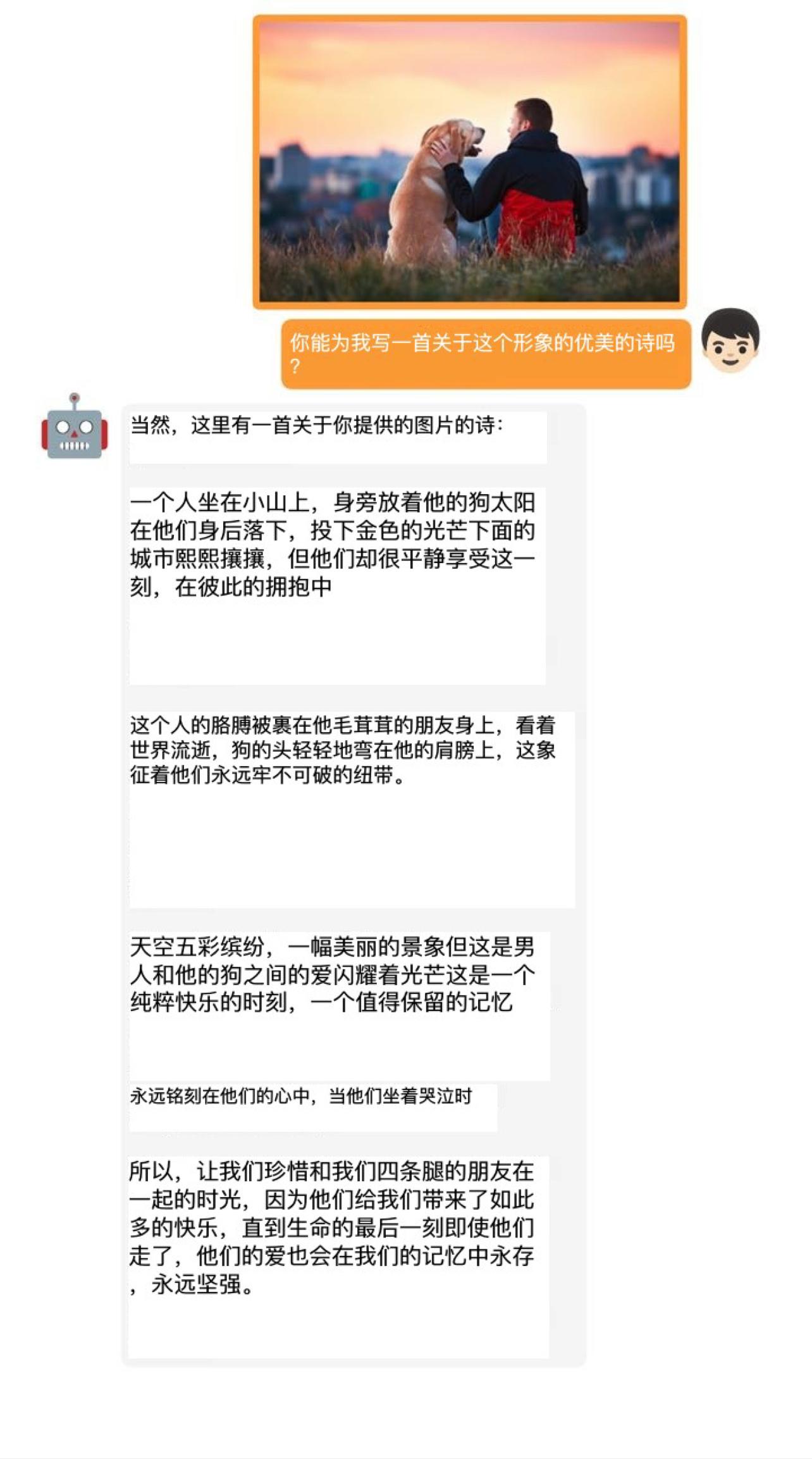
实验结果表明,GPT-4的这些先进能力理论上可以归因于它采用了更加先进的大型语言模型。
这意味着,未来在图像、声音、视频等领域,基于这些大型语言模型所开发的应用,在实际效果上都将表现不俗。
这个项目验证了大型语言模型在图像领域的可行性。接下来,预计会有更多开发者加入,将GPT-4的能力扩展至音频、视频等领域,从而让我们得以欣赏到更多有趣且令人惊艳的AI应用。
近日,我深入研究了许多关于ChatGPT注册和变现的实用干活信息。 为了方便我自己以后的学习和阅读,我整理了一些ChatGPT的操作技巧和实用工具:https://y3if3fk7ce.feishu.cn/docx/QBqwdyde7omVf4x69paconlgnAc
有兴趣的朋友们可以借此学习。